ÕģČÕ«×Õż¦Õ«ČķāĮń¤źķüōhadoopõĖ║µłæõ╗¼µÅÉõŠøõ║åõĖĆõĖ¬Õż¦ńÜäµĪåµ×Č’╝īń£¤µŁŻńÜäń«Śµ│ĢĶ┐śµś»Ķ”üń©ŗÕ║ÅÕæśĶć¬ÕĘ▒ÕÄ╗Õ«×ńÄ░’╝īµēĆõ╗źõ║åĶ¦ŻhadoopÕż¦µ”éµ×ȵ×äõ╣ŗÕÉÄÕ░▒Ķ”üõ║åĶ¦ŻõĖĆõ║øÕ¤║µ£¼ńÜäń«Śµ│ĢŃĆé
mahout--ÕÅ»õ╗źńÉåĶ¦ŻõĖ║hadoopńÜäķ®Šķ®ČÕæśŃĆéÕŁ”õ╣ĀÕ«āõĖĆÕ«ÜĶ”üõ╗ÄŃĆŖmahout in actionŃĆŗÕģźµēŗ’╝īÕ£©µŁżµłæĶ«░ÕĮĢõĖŗõĖĆõ║øÕŁ”õ╣ĀńÜäń¼öĶ«░õ╗ģõŠøÕÅéĶĆāŃĆé
┬Ā
ń¼¼õĖĆĶŖé’╝ÜÕ¤║õ║Äńö©µłĘńÜäµÄ©ĶŹÉń«Śµ│Ģ
GenericUserBasedRecommender ń«Śµ│ĢÕĤńÉå
Õ«śµ¢╣Ķ¦ŻķćŖ’╝Ü
for every other user w
compute a similarity s between u and w
retain the top users, ranked by similarity, as a ŌĆ£neighborhoodŌĆØ n
for every item i that some user in n has a preference for,
but that u has no preference for yet
for every other user v in n that has a preference for i
compute a similarity s between u and v
incorporate v's preference for i, weighted by s, into a running average
õĖĆ’╝ܵēƵ£ēńö©µłĘõĖÄńö©µłĘUÕüÜńøĖõ╝╝µĆ¦Ķ«Īń«Ś’╝īĶ«Īń«ŚÕć║ÕģČķé╗Õ▒ģķøåÕÉł n
┬Ā
õ║ī’╝ÜÕŠ¬ńÄ»µēƵ£ēńÜäÕĢåÕōü’╝īĶ«Īń«ŚÕć║ķé╗Õ▒ģķøåÕÉłnµ£ēÕģ┤ĶČŻõĖöńö©µłĘUµ▓Īµ£ēÕģ┤ĶČŻńÜäÕĢåÕōüķøåÕÉłitems
õĖē’╝ÜÕŠ¬ńÄ»itemsÕÆīķé╗Õ▒ģķøåÕÉłn’╝īĶ«Īń«ŚÕć║ķé╗Õ▒ģÕÆīńö©µłĘu ńÜäńøĖõ╝╝Õ║”sķøåÕÉł
Õøø’╝ÜĶ┐öÕø×sķøåÕÉłÕ╣ȵĀ╣µŹ«ńøĖõ╝╝Õ║”µÄÆÕ║ÅŃĆé
┬Ā
┬Ā
similarity ÕćĀõĖ¬õĖ╗Ķ”üń«Śµ│Ģ
Õ£©µŁżÕŬÕüÜõĖ╗Ķ”üõ╗ŗń╗Ź’╝īµä¤Õģ┤ĶČŻńÜäµ£ŗÕÅŗÕÅ»õ╗źńĀöń®ČõĖŗÕģĘõĮōÕģ¼Õ╝Å
┬Ā 1ŃĆüńÜ«Õ░öķĆŖńøĖÕģ│ń│╗µĢ░
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā ńö©õ║ÄÕ║”ķćÅõĖżõĖ¬ÕÅśķćÅXÕÆīYõ╣ŗķŚ┤ńÜäńøĖÕģ│’╝łń║┐µĆ¦ńøĖÕģ│’╝ē’╝īÕģČÕĆ╝õ╗ŗõ║Ä-1õĖÄ1õ╣ŗķŚ┤ŃĆéõĖżõĖ¬ÕÅśķćÅńøĖÕģ│µĆ¦ĶČŖķ½ś’╝īÕłÖń│╗µĢ░ĶČŗĶ┐æõ║Ä1’╝īõĖżõĖ¬ÕÅśķćÅńøĖõ║Æńŗ¼ń½ŗ’╝īÕłÖń│╗µĢ░õĖ║0’╝īõĖżń│╗µĢ░Õ»╣ń½ŗ’╝īÕłÖń│╗µĢ░ĶČŗĶ┐æõ║Ä0ŃĆ鵳æõ╗¼ń£ŗõĖŗõ╣”µ£¼õĖŖńÜäõŠŗÕŁÉ’╝Ü
┬Ā

┬Āõ╗ÄõĖŖÕøŠÕÅ»õ╗źń£ŗÕć║ user1 ÕÆī user4ńÜäńøĖÕģ│µĆ¦ µ»ö user1 ÕÆīuser5ńÜäńøĖÕģ│µĆ¦ķ½ś’╝īĶ┐Öõ╝╝õ╣ĵ£ēõĖĆõ║øcounterintuitiveŃĆé
┬ĀĶ┐śµ£ēuser1ÕÆīuser3µś»µ▓Īµ£ēńøĖÕģ│ń│╗µĢ░ńÜä’╝īĶ┐Öµś»ÕøĀõĖ║ń«Śµ│Ģń©ŗÕ║ÅńÜäĶ¦äÕłÖŃĆé
Ķ┐śµ£ēõĖĆń¦ŹµāģÕåĄõĖŗńøĖÕģ│µĆ¦µś»õĖŹĶ«Īń«ŚńÜä’╝īÕ”éµ×£õĖĆõĖ¬user Õ»╣µēƵ£ēńÜäitem ńÜäperference valueńøĖÕÉīŃĆé
õ╣”õĖŁõ╗ŗń╗ŹĶ┐Öń¦Źń«Śµ│ĢõĖŹÕźĮõĖŹÕØÅ’╝īõ╗ģõ╗ģĶ«®õĮĀńÉåĶ¦ŻõĖĆõĖŗÕ«āńÜäÕĘźõĮ£ÕĤńÉåÕ░▒ÕźĮõ║åŃĆé
┬Ā
┬Ā2ŃĆüµ¼¦ÕćĀķćīÕŠĘĶĘØń”╗ń«Śµ│Ģ
┬Ā┬Ā┬Ā┬Ā┬Ā Ķ»źń«Śµ│Ģµś»Õ¤║õ║ÄõĖżõĖ¬userõ╣ŗķŚ┤ńÜädistance’╝īµā│Ķ▒Īńö©µłĘńÜäÕØɵĀćÕ░▒µś»ńö©µłĘńÜäpreference values’╝īĶĘØń”╗ĶČŖÕ░Å’╝īÕłÖĶ»┤µśÄńö©µłĘńøĖõ╝╝Õ║”ĶČŖķ½śŃĆéĶ»źń«Śµ│ĢĶ┐öÕø×ÕĆ╝õĖ║ 1/(1+d),µēĆõ╗źÕĮōń«Śµ│ĢĶ┐öÕø×ÕĆ╝õĖ║1µŚČ’╝īĶĪ©ńż║õĖżńö©µłĘńøĖõ╝╝Õ║”Õ«īÕģ©ńøĖńŁēŃĆéń£ŗõĖŗõ╣”µ£¼õĖŖńÜäõŠŗÕŁÉ

┬ĀÕÅ»õ╗źń£ŗÕć║Ķ»źń«Śµ│ĢÕÆīńÜ«Õ░öķĆŖń│╗µĢ░µ£ēńøĖÕÉīńÜäķŚ«ķóś’╝īusers 1 and 4 have a higher similarity than users 1 and 5.
┬Ā
3ŃĆüõĮÖÕ╝”µĄŗķćÅńøĖõ╝╝Õ║”ń«Śµ│Ģ
┬Ā┬Ā┬Ā┬Ā õĮÖÕ╝”ńøĖõ╝╝Õ║”ńö©ÕÉæķćÅń®║ķŚ┤õĖŁõĖżõĖ¬ÕÉæķćÅÕż╣Ķ¦ÆńÜäõĮÖÕ╝”ÕĆ╝õĮ£õĖ║ĶĪĪķćÅõĖżõĖ¬õĖ¬õĮōķŚ┤ÕĘ«Õ╝éńÜäÕż¦Õ░ÅŃĆéńøĖµ»öĶĘØń”╗Õ║”ķćÅ’╝īõĮÖÕ╝”ńøĖõ╝╝Õ║”µø┤ÕŖĀµ│©ķćŹõĖżõĖ¬ÕÉæķćÅÕ£©µ¢╣ÕÉæõĖŖńÜäÕĘ«Õ╝é’╝īĶĆīķØ×ĶĘØń”╗µł¢ķĢ┐Õ║”õĖŖŃĆ鵳æõ╗¼ķ£ĆĶ”üń½ŗÕŹ│ńÜäÕ░▒µś»õĮÖÕ╝”ÕĆ╝Õ£©-1Õł░1õ╣ŗķŚ┤’╝īĶ¦ÆÕ║”ĶČŖÕ░Å’╝łńøĖõ╝╝Õ║”ĶČŖķ½ś’╝ēĶČŖĶČŗĶ┐æõ║Ä1ŃĆé
┬Ā4ŃĆü
ÕģČõĮÖµø┤ÕżÜń«Śµ│ĢĶ»ĘÕÅéĶĆā┬Ā http://www.cnblogs.com/shipengzhi/articles/2540382.html
┬Ā
┬Āń¼¼õ║īĶŖé’╝ÜÕ¤║õ║Äńē®ÕōüńÜäµÄ©ĶŹÉń«Śµ│Ģ
GenericItemBasedRecommender ń«Śµ│ĢÕĤńÉå
for every item i that u has no preference for yet
for every item j that u has a preference for
compute a similarity s between i and j
add u's preference for j, weighted by s, to a running average
return the top items, ranked by weighted average
┬ĀõĖĆ’╝ÜÕŠ¬ńÄ»µēƵ£ēńö©µłĘµ▓Īµ£ēÕüÅÕźĮńÜäńē®Õōü┬Ā i
┬Āõ║ī’╝ÜÕŠ¬ńÄ»µēƵ£ēńö©µłĘµ£ēÕüÅÕźĮńÜäńē®Õōü┬Ā j
┬ĀõĖē’╝ÜĶ«Īń«ŚiÕÆījńÜäńøĖõ╝╝Õ║” s
┬ĀÕøø’╝ÜõĖ║ńē®ÕōüjĶĄŗõ║ł ńøĖõ╝╝Õ║”
┬Āõ║ö’╝ÜĶ┐öÕø×µēƵ£ēńē®ÕōüµīēµØāķ揵ÄÆÕ║Å
┬Ā
ńøĖõ╝╝Õ║”ńøĖÕģ│ń«Śµ│ĢõŠŗÕ”é
public Recommender buildRecommender(DataModel model)
throws TasteException {
ItemSimilarity similarity = new PearsonCorrelationSimilarity(model);
return new GenericItemBasedRecommender(model, similarity);
}
┬Ā┬Ā ┬ĀÕÅ»õ╗źń£ŗÕł░Ķ┐ÖķćīPearsonCorrelationSimilarity õ╗ŹńäČÕÅ»õ╗źõĮ┐ńö©’╝īÕøĀõĖ║Õ«āÕ«×ńÄ░õ║åItemSimilarityµÄźÕÅŻ’╝īItemSimilarityµÄźÕÅŻÕ«īÕģ©ń▒╗õ╝╝UserSimilarityŃĆé
┬Ā┬Ā┬Ā GenericItemBasedRecommenderµ×äÕ╗║µ»öGenericUserBasedRecommenderń«ĆÕŹĢ’╝īÕ«āÕŬķ£ĆĶ”üõĖĆõĖ¬µĢ░µŹ«µ©ĪÕ×ŗdatamodel’╝īõĖĆõĖ¬ńøĖõ╝╝Õ║”ń«Śµ│Ģ’╝īĶĆīõĖŹķ£ĆĶ”üItemNeighborhood’╝īÕøĀõĖ║Õ£©ń«Śµ│ĢńÜäõĖĆÕ╝ĆÕ¦ŗ’╝īńö©µłĘÕ░▒ÕĘ▓ń╗ÅĶĪ©ĶŠŠõ║åĶć¬ÕĘ▒ńÜäÕüÅÕźĮ’╝īĶ┐ÖÕ░▒ń▒╗õ╝╝õ║ÄItemNeighborhoodŃĆé
┬Ā┬Ā┬Ā Õ£©ńē®ÕōüĶŠāńö©µłĘÕ░æńÜäµāģÕåĄõĖŗ’╝īÕ¤║õ║Äńē®ÕōüńÜäµÄ©ĶŹÉń«Śµ│ĢÕ░åĶ┐ÉĶĪīńÜäµø┤Õ┐½
┬Ā
┬Āń¼¼õĖēĶŖé’╝ÜSlope-one µÄ©ĶŹÉń«Śµ│Ģ

┬Ā
Õ»╣õ║ÄõĖŖķØóńÜäµĢ░µŹ«’╝īķ”¢ÕģłĶ«Īń«Śµ»ÅõĖ¬itemõ╣ŗķŚ┤ńÜäńøĖõ╝╝µĆ¦’╝īÕĮóµłÉitem-itemõ╣ŗķŚ┤ńÜäńøĖõ╝╝Õ║”Õģ│ń│╗ŃĆéńøĖõ╝╝Õ║”ńÜäĶ«Īń«ŚĶ┐ćń©ŗõĖŹµś»ķććńö©õĮÖÕ╝”ńøĖõ╝╝Õ║”Õģ¼Õ╝ÅńŁēµ¢╣µ│Ģ’╝īĶĆīµś»µĀ╣µŹ«ńö©µłĘõĖŁÕģ▒ÕÉīĶ»äÕłåńÜäitemńÜäÕĘ«ÕĆ╝Ķ┐øĶĪīĶ«Īń«ŚńÜäŃĆé
┬Ā
ńøĖõ╝╝Õ║”Ķ«Īń«Ś
õŠŗÕ”é’╝īitem 1õĖÄitem 2ńÜäńøĖõ╝╝Õ║”õĖ║ (2+(-1))/2=0.5ŃĆéõĮåµś»item 2õĖÄitem 1õ╣ŗķŚ┤ńÜäńøĖõ╝╝Õ║”õĖ║-0.5’╝īµĢ┤õĖ¬ńøĖõ╝╝Õ║”ń¤®ķśĄõĖŹµś»Õ»╣ń¦░ń¤®ķśĄŃĆéĶĆīµś»ÕÅŹÕ»╣ń¦░ń¤®ķśĄŃĆéõĖ║õ║åÕÉÄń╗Łµø┤µ¢░µ¢╣õŠ┐’╝īÕÅ»õ╗źÕ░åÕłåÕŁÉõĖÄÕłåµ»ŹÕłåÕł½ÕŁśÕé©’╝īńö©ńÜ䵌ČÕĆÖÕåŹĶ«Īń«ŚńøĖõ╝╝Õ║”ŃĆéÕÉīµĀĘńÜäµ¢╣µ│Ģ’╝īÕÅ»õ╗źĶ«Īń«Śitem1õĖÄitem 3õ╣ŗķŚ┤ńÜäńøĖõ╝╝Õ║”3ŃĆé
┬Ā
ķó䵥ŗĶ»äÕłå
ķó䵥ŗńÜ䵌ČÕĆÖ’╝īń«ĆÕŹĢńÜäÕŖĀµØāµś»Õ»╣õĖżõĖ¬itemÕģ▒ÕÉīĶ»äÕłåńÜäµĢ░ķćÅ’╝īõŠŗÕ”éitem1õĖÄitem2µ£ē2õĖ¬userÕģ▒ÕÉīĶ»äÕłåõ║å’╝īÕłÖµØāķ揵ś»2’╝īÕÉīµĀĘńÜäitem1õĖÄitem3ńÜäµØāķ揵ś»1ŃĆé
LucyÕ»╣item 1ńÜäķó䵥ŗĶ»äÕłåÕģ¼Õ╝ÅÕ”éõĖŗ’╝Ü
((2+0.5)*2+(3+5)*1)/(2+1)=4.33
Õ£©mahoutõĖŁµ£ēĶ┐ÖõĖ¬µ¢╣µ│ĢńÜäÕ«×ńÄ░ŃĆé
┬Ā
┬Āń¼¼õĖēĶŖé’╝ÜÕŹÅÕÉīĶ┐ćµ╗żõ╣ŗÕÉīńÄ░ń¤®ķśĄ
µĄŗĶ»ĢµĢ░µŹ«ķøå:small.csv
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.0
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0
1). Õ╗║ń½ŗńē®ÕōüńÜäÕÉīńÄ░ń¤®ķśĄ
µīēńö©µłĘÕłåń╗ä’╝īµēŠÕł░µ»ÅõĖ¬ńö©µłĘµēĆķĆēńÜäńē®Õōü’╝īÕŹĢńŗ¼Õć║ńÄ░Ķ«ĪµĢ░ÕÅŖõĖżõĖżõĖĆń╗äĶ«ĪµĢ░ŃĆé
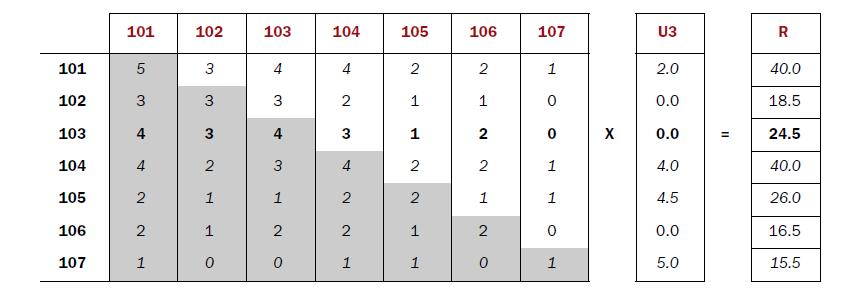
[101] [102] [103] [104] [105] [106] [107]
[101] 5 3 4 4 2 2 1
[102] 3 3 3 2 1 1 0
[103] 4 3 4 3 1 2 0
[104] 4 2 3 4 2 2 1
[105] 2 1 1 2 2 1 1
[106] 2 1 2 2 1 2 0
[107] 1 0 0 1 1 0 1
2). Õ╗║ń½ŗńö©µłĘÕ»╣ńē®ÕōüńÜäĶ»äÕłåń¤®ķśĄ
µīēńö©µłĘÕłåń╗ä’╝īµēŠÕł░µ»ÅõĖ¬ńö©µłĘµēĆķĆēńÜäńē®ÕōüÕÅŖĶ»äÕłå
U3
[101] 2.0
[102] 0.0
[103] 0.0
[104] 4.0
[105] 4.5
[106] 0.0
[107] 5.0
3). ń¤®ķśĄĶ«Īń«ŚµÄ©ĶŹÉń╗ōµ×£
ÕÉīńÄ░ń¤®ķśĄ*Ķ»äÕłåń¤®ķśĄ=µÄ©ĶŹÉń╗ōµ×£

- Õż¦Õ░Å: 15.1 KB

- Õż¦Õ░Å: 17 KB

- Õż¦Õ░Å: 23.8 KB
Õłåõ║½Õł░’╝Ü




ńøĖÕģ│µÄ©ĶŹÉ
MahoutõĮ£õĖ║ApacheńÜäÕ╝Ƶ║ɵ£║ÕÖ©ÕŁ”õ╣ĀķĪ╣ńø«’╝īµŖŖµÄ©ĶŹÉń│╗ń╗¤ŃĆüÕłåń▒╗ÕÆīĶüÜń▒╗ńŁēķóåÕ¤¤ńÜäµĀĖÕ┐āń«Śµ│ĢµĄōń╝®Õł░õ║åÕÅ»µē®Õ▒ĢńÜäńÄ░µłÉńÜäÕ║ōõĖŁŃĆéõĮ┐ńö©Mahout’╝īõĮĀÕÅ»õ╗źń½ŗÕŹ│Õ£©Ķć¬ÕĘ▒ńÜäķĪ╣ńø«õĖŁÕ║öńö©õ║Üķ®¼ķĆŖŃĆüNetflixÕÅŖÕģČõ╗¢õ║ÆĶüöńĮæÕģ¼ÕÅĖµēĆķććńö©ńÜäµ£║ÕÖ©ÕŁ”õ╣ĀµŖƵ£»ŃĆé, ...
┬Ę85õĖ¬Õ«×µłśÕÆīµĄŗĶ»ĢµŖƵ£»ŃĆĆ┬Ęń£¤Õ«×ńÜäÕ£║µÖ»’╝īÕ«×ńö©ńÜäĶ¦ŻÕå│µ¢╣µĪłŃĆĆ┬ĘÕ”éõĮĢµĢ┤ÕÉłMapReduceÕÆīRÕēŹĶ©Ć Ķć┤Ķ░óÕģ│õ║ĵ£¼õ╣” ń¼¼1 ķā©ÕłåŃĆĆĶāīµÖ»ÕÆīÕ¤║µ£¼ÕĤńÉå1ŃĆĆĶĘ│ĶĘāõĖŁńÜäHadoop1’╝Ä1ŃĆĆõ╗Ćõ╣łµś»Hadoop 1’╝Ä1’╝Ä1ŃĆĆHadoop ńÜäµĀĖÕ┐āń╗äõ╗Č1’╝Ä1’╝Ä2ŃĆĆHadoop ńö¤µĆüÕ£ł...
5’╝īMahoutÕēŹõĖĆķśČµ«ĄĶĪ©ńż║õ╗ÄńÄ░Õ£©ĶĄĘõ╗¢õ╗¼Õ░åõĖŹÕåŹµÄźÕÅŚõ╗╗õĮĢÕĮóÕ╝ÅńÜäõ╗źMapReduceÕĮóÕ╝ÅÕ«×ńÄ░ńÜäń«Śµ│Ģ’╝īÕÅ”Õż¢õĖƵ¢╣ķØó’╝īMahoutÕ«ŻÕĖāµ¢░ńÜäń«Śµ│ĢÕ¤║õ║ÄSpark’╝ø 6’╝īClouderańÜäµ£║ÕÖ©ÕŁ”õ╣ĀµĪåµ×ČOryxńÜäµē¦ĶĪīÕ╝ĢµōÄõ╣¤Õ░åńö▒HadoopńÜäMapReduceµø┐µŹóµłÉSpark’╝ø ...
4.µÅÉÕć║õ║åõĖĆń¦ŹÕ¤║õ║ÄĶŖéńé╣ÕŖ©µĆüµĆ¦ĶāĮµÄ©µ¢ŁńÜäõ╗╗ÕŖĪÕłåķģŹń«Śµ│ĢµĄĘķćÅńĮæń╗£µĢ░µŹ«ńÜäÕżäńÉåÕłåµ×ɵś»µĄĘķćÅńĮæń╗£µĢ░µŹ«ÕżäńÉåÕ╣│ÕÅ░µ£ĆõĖ║µĀĖÕ┐āńÜäÕŖ¤ĶāĮ,µĢ░µŹ«ÕżäńÉåńÜäµĢłńÄćÕģ│ń│╗Õł░µĢ┤õĖ¬µĄĘķćÅńĮæń╗£µĢ░µŹ«ÕżäńÉåÕ╣│ÕÅ░ńÜäµĆ¦ĶāĮ,ÕøĀµŁżÕ»╣õ║ÄĶ»źÕ╣│ÕÅ░µĢ░µŹ«ÕżäńÉåµĆ¦ĶāĮńÜäõ╝śÕī¢µś»µ£¼µ¢ćķ£ĆĶ”ü...
1’╝Ä1’╝Ä1ŃĆĆHadoop ńÜäµĀĖÕ┐āń╗äõ╗Č 1’╝Ä1’╝Ä2ŃĆĆHadoop ńö¤µĆüÕ£ł 1’╝Ä1’╝Ä3ŃĆĆńē®ńÉåµ×ȵ×ä 1’╝Ä1’╝Ä4ŃĆĆĶ░üÕ£©õĮ┐ńö©Hadoop 1’╝Ä1’╝Ä5ŃĆĆHadoop ńÜäÕ▒ĆķÖɵƦ 1’╝Ä2ŃĆĆĶ┐ÉĶĪīHadoop 1’╝Ä2’╝Ä1ŃĆĆõĖŗĶĮĮÕ╣ČÕ«ēĶŻģHadoop 1’╝Ä2’╝Ä2ŃĆĆHadoop ńÜäķģŹńĮ« 1’╝Ä2’╝Ä3ŃĆĆCLI ...
ńŖĆńēøĶ«ĪÕłÆ ķÜÅńØĆHadoopµē®Õ▒ĢÕł░µ¢░ÕĖéÕ£║Õ╣Čń£ŗÕł░µ¢░ńÜäńö©õŠŗķØóõĖ┤Õ«ēÕģ©µĆ¦ÕÆīÕÉłĶ¦äµĆ¦µīæµłś’╝īÕ┐ģķĪ╗Õ£©µēƵ£ēHadoopķĪ╣ńø«ÕÆī...Mahout’╝ܵ£║ÕÖ©ÕŁ”õ╣ĀÕÆīµĢ░µŹ«µī¢µÄśń«Śµ│ĢÕ║ō Flume’╝ܵöČķøåÕÆīÕ»╝ÕģźµŚźÕ┐ŚÕÆīõ║ŗõ╗ȵĢ░µŹ« Sqoop’╝Üõ╗ÄÕģ│ń│╗µĢ░µŹ«Õ║ōÕ»╝ÕģźµĢ░µŹ« Ķ┐Öõ║øµĀĖÕ┐āń╗äõ╗Čõ╗źÕÅŖ
MahoutÕēŹõĖĆķśČµ«ĄĶĪ©ńż║õ╗ÄńÄ░Õ£©ĶĄĘõ╗¢õ╗¼Õ░åõĖŹÕåŹµÄźÕÅŚõ╗╗õĮĢÕĮóÕ╝ÅńÜäõ╗źMapReduceÕĮóÕ╝ÅÕ«×ńÄ░ńÜäń«Śµ│Ģ’╝īÕÅ”Õż¢õĖƵ¢╣ķØó’╝īMahoutÕ«ŻÕĖāµ¢░ńÜäń«Śµ│ĢÕ¤║õ║ÄSpark’╝īÕÉīµŚČ’╝īĶ┐ÖÕćĀÕ╣┤µØź’╝īHadoopńÜäµö╣Ķ┐øÕ¤║µ£¼Õü£ńĢÖÕ£©õ╗ŻńĀüÕ▒éµ¼Ī’╝īõ╣¤Õ░▒µś»õ┐«õ┐«ĶĪźĶĪźńÜäõ║ŗµāģ’╝īĶ┐ÖÕ░▒Õ»╝Ķć┤õ║å...
Õ┐½ķƤ’╝ÜApache Sparkõ╗źÕåģÕŁśĶ«Īń«ŚõĖ║µĀĖÕ┐āŃĆé ķĆÜńö© ’╝ÜõĖĆń½ÖÕ╝ÅĶ¦ŻÕå│ÕÉäõĖ¬ķŚ«ķóś’╝īADHOC SQLµ¤źĶ»ó’╝īµĄüĶ«Īń«Ś’╝īµĢ░µŹ«µī¢µÄś’╝īÕøŠĶ«Īń«ŚÕ«īµĢ┤ńÜäńö¤µĆüÕ£łŃĆéÕŬĶ”üµÄīµÅĪSpark,Õ░▒ĶāĮÕż¤õĖ║Õż¦ÕżÜµĢ░ńÜäõ╝üõĖÜńÜäÕż¦µĢ░µŹ«Õ║öńö©Õ£║µÖ»µÅÉõŠøµśÄµśŠńÜäÕŖĀķƤŃĆéÕŁśÕé©Õ▒é’╝ÜHDFSõĮ£õĖ║...
10.6 Mahout õĖŁńÜäµÄ©ĶŹÉń«Śµ│ĢŌĆ”ŌĆ”.. ... .... 313 10.7 ńöĄÕĢåÕĖĖĶ¦üńÜäµÄ©ĶŹÉń│╗ń╗¤µ¢╣µĪłŌĆ”ŌĆ”ŌĆ” 314 10.7.1 ńöĄÕĢåÕĖĖĶ¦üńÜäµÄ©ĶŹÉń│╗ń╗¤ µ¢╣µĪłŌĆ”ŌĆ”ŌĆ”ŌĆ”ŌĆ”ŌĆ”ŌĆ”ŌĆ”ŌĆ”.. 314 10.7.2 ńøĖõ╝╝Õ║”ńÜäĶ«Īń«Ś ŌĆ”ŌĆ”ŌĆ”ŌĆ”ŌĆ”.. 317 10.7.3 ÕŹÅÕÉīĶ┐ćµ╗żŌĆ”ŌĆ”ŌĆ”ŌĆ”...
ĶĘæÕ£©hadoopÕ╣│ÕÅ░õĖŖńÜ䵥ŗĶ»Ģõ╗ŻńĀü’╝īÕÆīÕ«×ķÖģĶ┐ÉĶĪīÕ£©Õ╣│ÕÅ░õĖŖńÜäõ╗ŻńĀüµ£ēõ║øõĖŹÕÉīµĀĖÕ┐āÕŖ¤ĶāĮķā©Õłåõ╗ŻńĀüńÜäµĢ░µŹ«ÕćåÕżćµś»Õł®ńö©Nutch ńł¼ÕÅ¢ ńĮæµśōķŚ©µłĘńĮæń½ÖõĖŁÕÉäõĖ¬Õłåń▒╗ńÜäÕåģÕ«╣’╝īµĀ╣µŹ«ÕåģÕ«╣Ķ┐øĶĪīÕłåĶ»Ź’╝łÕł®ńö©Lucene’╝īķģŹńĮ«Õ║¢õĖüĶ¦ŻńēøÕīģńÜäķģŹńĮ«µ¢ćõ╗Č’╝ēńäČÕÉÄÕł®ńö©...
Õ¤║õ║ÄHadoopµØźÕ«×ńÄ░ńÜäń╗ÅÕģĖń«Śµ│Ģ’╝īµŗ┐Ķ┐ÖõĖ¬õĮ£õĖ║µĢ░µŹ«Õłåµ×ÉńÜäµĀĖÕ┐āń«Śµ│ĢķøåµØźÕÅéĶĆāĶ┐śµś»ÕŠłÕźĮńÜäŃĆé Õż¦µĢ░µŹ«Õłåµ×ÉÕ╣│ÕÅ░Õģ©µ¢ćÕģ▒4ķĪĄ’╝īÕĮōÕēŹõĖ║ń¼¼2ķĪĄŃĆé Õż¦µĢ░µŹ«Õłåµ×ÉÕ╣│ÕÅ░Õģ©µ¢ćÕģ▒4ķĪĄ’╝īÕĮōÕēŹõĖ║ń¼¼2ķĪĄŃĆé Õ”éµŁżõĖĆõĖ¬Õå│ńŁ¢µö»µīüń│╗ń╗¤Ķ”üµĆÄõ╣łÕ▒ĢńÄ░Õæó’╝¤ÕģČÕ«×Ķ┐ÖõĖ¬ÕÆī...